This section contains unsorted documents imported from our GitHub wiki.
Edit on GitHub
Unsorted docs from GitHub wiki
_Sidebar
[[Home]]
[[Getting-Started]]
[[FAQ]]
[[Benchmarks]]
[[Known Issues]]
[[Instructions]]
[[Debug and test procedures]]
[[Neural Net Training]]
[[Project History]]
[[Why Zero]]
[[lc0 transition]]
[[Training runs]]
[[TCEC]]
[[CLOP tuning]]
[[Third Party Nets]]
android
[[Home]]
[[Getting-Started]]
[[FAQ]]
[[Benchmarks]]
[[Known Issues]]
[[Instructions]]
[[Debug and test procedures]]
[[Neural Net Training]]
[[Project History]]
[[Why Zero]]
[[lc0 transition]]
[[Training runs]]
[[TCEC]]
[[CLOP tuning]]
[[Third Party Nets]]
[[What is Lc0? (for non programmers)]]
Batchsize Node Collisions Testing
1024 bs 256 nc (cccc 2 params) vs default so far.
Score of lc0 v18 1024 vs lc0 v18: 33 - 45 - 89 [0.464]
Elo difference: -25.01 +/- 36.08
Trying medium vs large batchsize. 1024 batchsize and 256 node cccc vs TCEC 512/32.
Beginner Friendly Guide on Training and Testing a Net on Google Colab
Introduction
This is intended to be a beginner-friendly guide on how to train and bench (against the CCRL Baseline Net) lczero neural networks. This is probably the place to look if you’re stuck with no GPU / an AMD one (as I am), and if you don’t use linux. If you don’t fall into both or either of these categories, I still hope you’ll be able to take away something from this.
Benchmarks
Run go infinite from start position and abort after depth 26 and report NPS output.
I put some sample ones from memory. Please put your own bench scores here in sorted NPS order if you can. If you don’t know what engine type, gpu is opencl and cpu is openblas
Best Nets for Lc0
The networks below are our strongest available. In general, the largest network compatible with your hardware is recommended. To download, right click the corresponding link and select “Save link as…”
Building lc0 on Android, with Termux
Important: If you just want to run lc0 on your Android device then the steps described here are no longer needed. Now there’s an easier way to run lc0 without having to build it your own. Check it out:
Building lc0 with Termux
Important: If you just want to run lc0 on your Android device then the steps described here are no longer needed. Now there’s an easier way to run lc0 without having to build it your own. Check it out:
CCCC
The Chess.com Computer Chess Championship (CCCC) is continuously running computer chess events and is maintained by Chess.com at https://www.chess.com/computer-chess-championship.
CCC 17 Blitz: Finals
| Executable | Network | Placement | Result |
|---|---|---|---|
| v0.30.0-dev dag-bord (5e84a3) | 784038 | 2/2 | 192/480 |
Finals Ordo evaluation:
# ENGINE : RATING ERROR CFS(%) W D L GAMES DRAWS(%)
1 Stockfish : 71 22 100.0 134 308 38 480 64.2
2 Lc0 : 0 ---- --- 38 308 134 480 64.2
LC0 hardware and settings:
- Hardware: 2x A100, 2x AMD EPYC 7H12, 256 cores (128 physical)
- Non-default parameters:
- Backend=demux
- BackendOptions=backend=cuda-fp16,(gpu=0),(gpu=1)
- MinibatchSize=384
- MaxPrefetch=37
- NNCacheSize=20000000
- CPuct=1.988
- CPuctBase=45669
- CPuctFactor=3.973
- FpuValue=0.290
- PolicyTemperature=1.186
- SmartPruningFactor=2.0
- SmartPruningMinimumBatches=300
- StrictTiming=true
CCC Rapid 2021: Finals
| Executable | Network | Placement | Result |
|---|---|---|---|
| v0.27.0-rc1 | J94-100 | 2/2 | 219.5/500 |
Finals Ordo evaluation:
# ENGINE : RATING ERROR CFS(%) W D L GAMES DRAWS(%)
1 Stockfish : 43 22 100.0 122 317 61 500 63.4
2 Lc0 : 0 ---- --- 61 317 122 500 63.4
LC0 hardware and settings:
- Hardware: 2x A100, 2x AMD EPYC 7H12, 256 cores (128 physical)
- Non-default parameters:
- Backend=demux
- BackendOptions=backend=cuda-fp16,res_block_fusing=true,(gpu=0),(gpu=1)
- MinibatchSize=192
- MaxPrefetch=48
- MultiGather=true
- MaxCollisionEvents=917
- MaxCollisionVisits=1000
- MaxOutOfOrderEvalsFactor=2.4
- NNCacheSize=20000000
- SmartPruningMinimumBatches=100
- TimeManager=legacy(steepness=4.0)
- MoveOverheadMs=1000
- StrictTiming=true
CLOP tuning
CLOP Tuning is a tool used for figuring out what differentiable constants, functions, or other things should gain lc0 the most Elo/improve performance.
CLOP Tuner:
https://github.com/kiudee/bayes-skopt
TCEC Season 13 tuning
Master (and thus div4) is result of a CLOP tune at 4000 games. Div3 updated the prune factor and time scale based on results at 8000 games as CLOP continued to run during div4.
Contributing Training Games
Contribute
Use the below resources to contribute to the project through FREE google credits
-
[[Run LC0 client on Google Cloud|Google-Cloud-guide-(lc0)]]
- [[Run LC0 client on Google Colab|Run-Leela-Chess-Zero-client-on-a-Tesla-K80-GPU-for-free-(Google-Colaboratory)]]
Use the link below if you want to contribute with your own hardware
Debug and test procedures
Example tournament command line
./cutechess-cli -rounds 100 -tournament gauntlet -concurrency 2 -pgnout results.pgn \
-engine name=lc_gen13_fpu cmd=lczero_fpu arg="--threads=1" arg="--weights=$WDR/cd1a1e" arg="--playouts=800" arg="--noponder" arg="--noise" tc=inf \
-engine name=lc_gen13 cmd=lczero arg="--threads=1" arg="--weights=$WDR/cd1a1e" arg="--playouts=800" arg="--noponder" arg="--noise" tc=inf \
-each proto=uci
Analysis of positions
(I think with some upcoming patches we can do this in GUIs together with -l lzcdebug.log).
Dubslow's analysis of Test 10 problems
So, the major assumption that goes into this is that the Tensorboard data is a reliable sole source of information for the information it provides. That’s quite reasonable (if it wasn’t we may as well give up the project), but it’s also in contrast to the various Elo measurements we have, none of which are a single sole reliable source of playing strenth – instead they all need to be considered collectively.
FAQ
Where do I start?
- To contribute to the project, see [[Getting Started]] and follow the instructions for running self-play training games.
- To just run the engine locally, see [[Getting Started]] and follow the instructions for running the engine. See also [[Running Leela Chess Zero in a Chess GUI]] for instruction on various popular GUIs.
How does Leela Chess Zero work?
- For non-programmers, there is a simplified explanation of Leela Chess Zero here.
- A nice [[Technical Explanation of Leela Chess Zero]] and glossary of technical terms is available.
- The self-play games your client creates are used by the central server to improve the neural net. See [[Neural Net Training]] for more details. You can also see a summary of the [[Training runs]]
How can I follow project status and plans?
- See our blog
- Discord chat #announcements and #dev-log have the most detailed updates.
- Our github projects page shows plans for current and future work.
What is the current strength of Lc0?
The Elo chart seems inflated.
- The chart is not calibrated to CCRL or any other common list. It sets ’the first net’ to Elo 0, so it is not comparable, even between different training runs.
- The different points are calculated from self-play matches. Self-play tends to exaggerate gains in Elo compared to gains when playing other chess engines.
Where can I find Lc0’s current Elo?
Many people test the strength of Lc0 nets but the main exchange of results is now the test-results channel of the Lc0 chat on discord. Most web pages are no longer or only occasionally updated. Status as of 2019-10-14:
Getting Started
Basics
- To help the project by donating GPU time, here’s the gist of what you need to do:
- Download and install the Client and Engine
- Run the client.exe
The client will run games and arrange all communication with the learning server. Thanks for contributing!
Google Cloud guide (lc0)
This guide will allow you to have Leela Chess Zero clients running in the cloud in 10 minutes or less. These clients will run self-play training games and help make Leela stronger. This guide is aimed at everyone and assumes no technical understanding.
Home
- FAQ
- Getting started
- Networks
- LC0 Options
- Benchmarking
- Project History
- Tournament History:
- Knowledge Base:
- Guides:
- Running
- Building/Compiling
- Training Networks
- Running/Contributing with Google Colab
- Running/Contributing with vast.ai
- Running/Contributing in Docker
- Running as a Bot
- Debugging:
- Testing:
- Tuning:
- Known Issues
Instructions
Below a list of Guides / instructions for various task.
- [[Google Cloud guide (lc0)]]
To contribute to the project for free - [[Run Leela Chess Zero client on a Tesla K80 GPU for free (Google Colaboratory)]]
- [[Running lczero with cuda and cudnn under nvidia docker2]]
- [[Running Leela Chess Zero as a Lichess Bot]]
- [[Running Leela Chess Zero in a Chess GUI]]
- [[Running Leela Chess Zero in a Chess GUI (lc0)]]
- [[Running Leela Chess Zero on Intel CPUs (Haswell or later)]]
- [[Ubuntu 16.04 LC0 Instructions]]
- [[Ubuntu 16.04 MKL Instructions]]
- [[Script for testing new nets versus old nets on Google Colab]]
- [[Leela Self play in Docker]]
Known Issues
There are several known issues with Leela Chess Zero play and training runs. Some of them have already been solved and are listed for “historical documentation”, while others are still being investigated.
Large Elo fluctuations starting from ID253
Below is a brief summary of our investigation into the issues that started showing up in the Elo graph from ID253. We have been performing a number of tests that require changing parameters, generating new self-play games, and training on those. This process requires many self-play games, so your help generating them is still invaluable! We have some promising leads, but still require more time and testing. Thank you for your patience.
Lc0 for 32 bit windows
32 bit processors and operating systems are supported by lc0. However CUDNN is not available for such platforms, so only the blas and opencl backends can be built.
There are no official builds distributed, but the latest version available can be found using the following links:
Lc0 options
Lc0 options
| Flag | UCI option | Description |
|---|---|---|
| –help, -h | Show help and exit. | |
| –weights, -w | WeightsFile | Path from which to load network weights.Setting it to <autodiscover> makes it search in ./ and ./weights/ subdirectories for the latest (by file date) file which looks like weights.Default value: <autodiscover> |
| –backend, -b | Backend | Neural network computational backend to use.Default value: cudnn Allowed values: cudnn, cudnn-fp16, opencl, blas, check, random, roundrobin, multiplexing, demux |
| –backend-opts, -o | BackendOptions | Parameters of neural network backend. Exact parameters differ per backend. |
| –threads, -t | Threads | Number of (CPU) worker threads to use.Default value: 2 Minimum value: 1 Maximum value: 128 |
| –nncache | NNCacheSize | Number of positions to store in a memory cache. A large cache can speed up searching, but takes memory.Default value: 200000 Minimum value: 0 Maximum value: 999999999 |
Search options
| Flag | UCI option | Description |
|---|---|---|
| –minibatch-size | MinibatchSize | How many positions the engine tries to batch together for parallel NN computation. Larger batches may reduce strength a bit, especially with a small number of playouts.Default value: 256 Minimum value: 1 Maximum value: 1024 |
| –max-prefetch | MaxPrefetch | When the engine cannot gather a large enough batch for immediate use, try to prefetch up to X positions which are likely to be useful soon, and put them into cache.Default value: 32 Minimum value: 0 Maximum value: 1024 |
| –cpuct | CPuct | cpuct_init constant from “UCT search” algorithm. Higher values promote more exploration/wider search, lower values promote more confidence/deeper search.Default value: 3.00 Minimum value: 0.00 Maximum value: 100.00 |
| –cpuct-base | CPuctBase | cpuct_base constant from “UCT search” algorithm. Lower value means higher growth of Cpuct as number of node visits grows.Default value: 19652.00 Minimum value: 1.00 Maximum value: 1000000000.00 |
| –cpuct-factor | CPuctFactor | Multiplier for the cpuct growth formula.Default value: 2.00 Minimum value: 0.00 Maximum value: 1000.00 |
| –temperature | Temperature | Tau value from softmax formula for the first move. If equal to 0, the engine picks the best move to make. Larger values increase randomness while making the move.Default value: 0.00 Minimum value: 0.00 Maximum value: 100.00 |
| –tempdecay-moves | TempDecayMoves | Reduce temperature for every move from the game start to this number of moves, decreasing linearly from initial temperature to 0. A value of 0 disables tempdecay.Default value: 0 Minimum value: 0 Maximum value: 100 |
| –temp-cutoff-move | TempCutoffMove | Move number, starting from which endgame temperature is used rather than initial temperature. Setting it to 0 disables cutoff.Default value: 0 Minimum value: 0 Maximum value: 1000 |
| –temp-endgame | TempEndgame | Temperature used during endgame (starting from cutoff move). Endgame temperature doesn’t decay.Default value: 0.00 Minimum value: 0.00 Maximum value: 100.00 |
| –temp-value-cutoff | TempValueCutoff | When move is selected using temperature, bad moves (with win probability less than X than the best move) are not considered at all.Default value: 100.00 Minimum value: 0.00 Maximum value: 100.00 |
| –temp-visit-offset | TempVisitOffset | Reduces visits by this value when picking a move with a temperature. When the offset is less than number of visits for a particular move, that move is not picked at all.Default value: 0.00 Minimum value: -1.00 Maximum value: 1000.00 |
| –noise, -n | DirichletNoise | Add Dirichlet noise to root node prior probabilities. This allows the engine to discover new ideas during training by exploring moves which are known to be bad. Not normally used during play.Default value: false |
| –verbose-move-stats | VerboseMoveStats | Display Q, V, N, U and P values of every move candidate after each move.Default value: false |
| –smart-pruning-factor | SmartPruningFactor | Do not spend time on the moves which cannot become bestmove given the remaining time to search. When no other move can overtake the current best, the search stops, saving the time. Values greater than 1 stop less promising moves from being considered even earlier. Values less than 1 causes hopeless moves to still have some attention. When set to 0, smart pruning is deactivated.Default value: 1.33 Minimum value: 0.00 Maximum value: 10.00 |
| –fpu-strategy | FpuStrategy | How is an eval of unvisited node determined. “reduction” subtracts --fpu-reduction value from the parent eval. “absolute” sets eval of unvisited nodes to the value specified in --fpu-value.Default value: reduction Allowed values: reduction, absolute |
| –fpu-reduction | FpuReduction | “First Play Urgency” reduction (used when FPU strategy is “reduction”). Normally when a move has no visits, it’s eval is assumed to be equal to parent’s eval. With non-zero FPU reduction, eval of unvisited move is decreased by that value, discouraging visits of unvisited moves, and saving those visits for (hopefully) more promising moves.Default value: 1.20 Minimum value: -100.00 Maximum value: 100.00 |
| –fpu-value | FpuValue | “First Play Urgency” value. When FPU strategy is “absolute”, value of unvisited node is assumed to be equal to this value, and does not depend on parent eval.Default value: -1.00 Minimum value: -1.00 Maximum value: 1.00 |
| –cache-history-length | CacheHistoryLength | Length of history, in half-moves, to include into the cache key. When this value is less than history that NN uses to eval a position, it’s possble that the search will use eval of the same position with different history taken from cache.Default value: 0 Minimum value: 0 Maximum value: 7 |
| –policy-softmax-temp | PolicyTemperature | Policy softmax temperature. Higher values make priors of move candidates closer to each other, widening the search.Default value: 2.20 Minimum value: 0.10 Maximum value: 10.00 |
| –max-collision-events | MaxCollisionEvents | Allowed node collision events, per batch.Default value: 32 Minimum value: 1 Maximum value: 1024 |
| –max-collision-visits | MaxCollisionVisits | Total allowed node collision visits, per batch.Default value: 9999 Minimum value: 1 Maximum value: 1000000 |
| –out-of-order-eval | OutOfOrderEval | During the gathering of a batch for NN to eval, if position happens to be in the cache or is terminal, evaluate it right away without sending the batch to the NN. When off, this may only happen with the very first node of a batch; when on, this can happen with any node.Default value: true |
| –syzygy-fast-play | SyzygyFastPlay | With DTZ tablebase files, only allow the network pick from winning moves that have shortest DTZ to play faster (but not necessarily optimally).Default value: true |
| –multipv | MultiPV | Number of game play lines (principal variations) to show in UCI info output.Default value: 1 Minimum value: 1 Maximum value: 500 |
| –score-type | ScoreType | What to display as score. Either centipawns (the UCI default), win percentage or Q (the actual internal score) multiplied by 100.Default value: centipawn Allowed values: centipawn, win_percentage, Q |
| –history-fill | HistoryFill | Neural network uses 7 previous board positions in addition to the current one. During the first moves of the game such historical positions don’t exist, but they can be synthesized. This parameter defines when to synthesize them (always, never, or only at non-standard fen position).Default value: fen_only Allowed values: no, fen_only, always |
| –kldgain-average-interval | KLDGainAverageInterval | Used to decide how frequently to evaluate the average KLDGainPerNode to check the MinimumKLDGainPerNode, if specified.Default value: 100 Minimum value: 1 Maximum value: 10000000 |
| –minimum-kldgain-per-node | MinimumKLDGainPerNode | If greater than 0 search will abort unless the last KLDGainAverageInterval nodes have an average gain per node of at least this much.Default value: 0.00 Minimum value: 0.00 Maximum value: 1.00 |
Engine options
| Flag | UCI option | Description |
|---|---|---|
| –slowmover | Slowmover | Budgeted time for a move is multiplied by this value, causing the engine to spend more time (if value is greater than 1) or less time (if the value is less than 1).Default value: 1.00 Minimum value: 0.00 Maximum value: 100.00 |
| –move-overhead | MoveOverheadMs | Amount of time, in milliseconds, that the engine subtracts from it’s total available time (to compensate for slow connection, interprocess communication, etc).Default value: 200 Minimum value: 0 Maximum value: 100000000 |
| –time-midpoint-move | TimeMidpointMove | The move where the time budgeting algorithm guesses half of all games to be completed by. Half of the time allocated for the first move is allocated at approximately this move.Default value: 51.50 Minimum value: 1.00 Maximum value: 100.00 |
| –time-steepness | TimeSteepness | “Steepness” of the function the time budgeting algorithm uses to consider when games are completed. Lower values leave more time for the endgame, higher values use more time for each move before the midpoint.Default value: 7.00 Minimum value: 1.00 Maximum value: 100.00 |
| –syzygy-paths, -s | SyzygyPath | List of Syzygy tablebase directories, list entries separated by system separator (";" for Windows, “:” for Linux). |
| –ponder | Ponder | This option is ignored. Here to please chess GUIs.Default value: true |
| –immediate-time-use | ImmediateTimeUse | Fraction of time saved by smart pruning, which is added to the budget to the next move rather than to the entire game. When 1, all saved time is added to the next move’s budget; when 0, saved time is distributed among all future moves.Default value: 1.00 Minimum value: 0.00 Maximum value: 1.00 |
| –ramlimit-mb | RamLimitMb | Maximum memory usage for the engine, in megabytes. The estimation is very rough, and can be off by a lot. For example, multiple visits to a terminal node counted several times, and the estimation assumes that all positions have 30 possible moves. When set to 0, no RAM limit is enforced.Default value: 0 Minimum value: 0 Maximum value: 100000000 |
| –config, -c | ConfigFile | Path to a configuration file. The format of the file is one command line parameter per line, e.g.:--weights=/path/to/weightsDefault value: lc0.config |
| –logfile, -l | LogFile | Write log to that file. Special value <stderr> to output the log to the console. |
Selfplay options
| Flag | UCI option | Description |
|---|---|---|
| –share-trees | ShareTrees | When on, game tree is shared for two players; when off, each side has a separate tree.Default value: true |
| –games | Games | Number of games to play.Default value: -1 Minimum value: -1 Maximum value: 999999 |
| –parallelism | Parallelism | Number of games to play in parallel.Default value: 8 Minimum value: 1 Maximum value: 256 |
| –playouts | Playouts | Number of playouts per move to search.Default value: -1 Minimum value: -1 Maximum value: 999999999 |
| –visits | Visits | Number of visits per move to search.Default value: -1 Minimum value: -1 Maximum value: 999999999 |
| –movetime | MoveTime | Time per move, in milliseconds.Default value: -1 Minimum value: -1 Maximum value: 999999999 |
| –training | Training | Enables writing training data. The training data is stored into a temporary subdirectory that the engine creates.Default value: false |
| –verbose-thinking | VerboseThinking | Show verbose thinking messages.Default value: false |
| –resign-playthrough | ResignPlaythrough | The percentage of games which ignore resign.Default value: 0.00 Minimum value: 0.00 Maximum value: 100.00 |
| –reuse-tree | ReuseTree | Reuse the search tree between moves.Default value: false |
| –resign-wdlstyle | ResignWDLStyle | If set, resign percentage applies to any output state being above 100% minus the percentage instead of winrate being below.Default value: false |
| –resign-percentage | ResignPercentage | Resign when win percentage drops below specified value.Default value: 0.00 Minimum value: 0.00 Maximum value: 100.00 |
| –resign-earliest-move | ResignEarliestMove | Earliest move that resign is allowed.Default value: 0 Minimum value: 0 Maximum value: 1000 |
| –interactive | Run in interactive mode with UCI-like interface.Default value: false |
Benchmark options
| Flag | UCI option | Description |
|---|---|---|
| –nodes | Number of nodes to run as a benchmark.Default value: -1 Minimum value: -1 Maximum value: 999999999 |
|
| –movetime | Benchmark time allocation, in milliseconds.Default value: 10000 Minimum value: -1 Maximum value: 999999999 |
|
| –fen | Benchmark initial position FEN.Default value: rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1 |
Leela Chess Zero Wiki
Wiki Overview
- FAQ
- Getting started
- Best Networks
- LC0 Options
- Benchmarking
- Guides:
- Running LC0 in a Chess GUI
- Running LC0 on Android with a Chess GUI
- Building LC0 with Termux
- Running LC0 on Intel CPUs (Haswell or later)
- Ubuntu 16.04 LC0 Instructions
- Ubuntu 16.04 MKL Instructions
- Google Cloud Guide (LC0)
- Run LC0 client on a Tesla K80 GPU for free (Google Colaboratory)
- Beginner Friendly Guide on Training and Testing a Net on Google Colab
- Running LC0 with cuda and cudnn under nvidia docker2
- Leela Self play in Docker
- Script for testing new nets versus old nets on Google Colab
- Running LC0 as a Lichess Bot
- Neural Net Training
- Debug and test procedures
- Testing:
- Tuning:
- Project History
- Tournament History:
- Known Issues
Leela Self play in Docker
Docker
-
Install docker for your box
-
Create temporary folder
mkdir ~/temp && cd ~/temp -
Create a file named
Dockerfileand paste the following
From ubuntu:latest
RUN apt-get update
RUN apt install g++ git libboost-all-dev libopenblas-dev opencl-headers ocl-icd-libopencl1 ocl-icd-opencl-dev zlib1g-dev cmake wget supervisor curl -y
RUN apt install clinfo && clinfo
RUN mkdir /lczero && \
cd ~ && \
git clone https://github.com/glinscott/leela-chess.git &&\
cd leela-chess &&\
git submodule update --init --recursive &&\
mkdir build && cd build &&\
#for gpu build
#cmake .. && \
#for cpu build
cmake -DFEATURE_USE_CPU_ONLY=1 .. &&\
make -j$(nproc) && \
cp lczero /lczero && \
cd /lczero && \
curl -s -L https://github.com/glinscott/leela-chess/releases/latest | egrep -o '/glinscott/leela-chess/releases/download/v.*/client_linux' | head -n 1 | wget --base=http://github.com/ -i - && \
chmod +x client_linux
COPY supervisord.conf /etc/supervisor/conf.d/
RUN service supervisor start
if you want to build for GPU comment out cmake -DFEATURE_.... and uncomment cmake ..
Main
Welcome to the Leela Chess Zero wiki!
Lc0 is a UCI-compliant chess engine designed to play chess via neural network
Play Chess with LC0
- [[Getting-Started]] - Download and run lc0.exe to play/analyze games.
- [[Running Leela Chess Zero in a Chess GUI]]
[[FAQ]]
- Find the answers to [[Frequently Asked Question|FAQ]]
Contribute
Use the below resources to contribute to the project through FREE google credits
Missing Shallow Tactics
Leela Chess is known to miss relatively shallow tactics in relation to the high level of play. The below is a rough draft explaining how the search works and why it misses shallow tactics.
Networks
The networks below are our strongest available, and the first listed (BT4-spsa-1740) is what is currently being sent to engine competitions like the TCEC and CCC. In general, the largest network compatible with your hardware is recommended. To download, right click the corresponding link and select “Save link as…”
Neural Net Training
The self-play games your client creates are used by the central server to improve the neural net. This process is called training (many people call the process of running the client to produce self-play games training, but in machine learning these games are only the input data for the actual training process).
Overview
- FAQ
- Getting started
- Best Networks
- LC0 Options
- Benchmarking
- Guides:
- Running LC0 in a Chess GUI
- Running LC0 on Android with a Chess GUI
- Building LC0 with Termux
- Running LC0 on Intel CPUs (Haswell or later)
- Ubuntu 16.04 LC0 Instructions
- Ubuntu 16.04 MKL Instructions
- Google Cloud Guide (LC0)
- Run LC0 client on a Tesla K80 GPU for free (Google Colaboratory)
- Beginner Friendly Guide on Training and Testing a Net on Google Colab
- Running LC0 with cuda and cudnn under nvidia docker2
- Leela Self play in Docker
- Script for testing new nets versus old nets on Google Colab
- Running LC0 as a Lichess Bot
- Neural Net Training
- Debug and test procedures
- Testing:
- Tuning:
- Project History
- Tournament History:
- Known Issues
Project History
- See also our blog
- Discord chat #announcements and #dev-log have the most detailed updates.
T80
- Start date: 2022-04-03
- Network size: 15 residual blocks, 512 filters
- Attention policy head with 0 encoder layers, ReLU activations replaced with mish
- Training started from an initial net trained by tilps on T79 data for ~2m steps
- Initial learning rate of 0.04
- 800127: Reduced to 1k steps per net (64k games)
- 800226: Learning rate drop to 0.004, reg. term weight 0.15, back up to 2k steps per net
- 800784: Reduced to 1k steps per net again (64k games)
- 801910: Reduced to 500 steps per net (64k games)
T79
- Start date: 2022-02-25
- Network size: 15 residual blocks, 192 filters
- Attention policy head with 0 encoder layers, ReLU activations replaced with mish
- 790202: KLD dropped from 60 to 50 micronats
- 790243: Policy softmax temperature set to 1.45 (up from 1.40)
- 790264: Reverted last policy softmax temperature change
- 790279: Learning rate drop to 0.04
- 790401: Reg term weight set to 0.75
- 790451: Reg term weight set to 0.6
- 790503: Reg term weight set to 0.5
- 790612: Policy softmax temperature set to 1.45… again (up from 1.40)
- 790652: Learning rate drop to 0.004, reg term weight set to 0.15
- 790994: Reg term weight to 0.1
- 791071: Fpu value set to 0.26 (up from 0.23)
- 791334: Learning rate drop to 0.0004, reg term weight set to 0.05
- 791770: Learning rate drop to 0.00004
- 791971: Reg term weight disabled
- End date: 2022-05-20
T78
- Start date: 2021-12-03
- Network size: 40 residual blocks, 512 filters
- Training started from an initial net trained by masterkni6
- Initial learning rate of 0.0002
T77
- Start date: 2021-11-21
- Network size: 15 residual blocks, 192 filters
- Input format 4
- 770041: KLD set to 40 micronats (down from 60)
- 770252: Learning rate drop to 0.04, reg term weight set to 0.5
- 770559: Learning rate drop to 0.004, reg term weight set to 0.15
- 771043: Reg term weight set to 0.1
- 771258: Learning rate drop to 0.0004 and reg term weight to 0.05
- 771548: Learning rate drop to 0.00004 and reg term weight to 0.02
- End date: 2021-12-31
T76
- Start date: 2021-10-16
- Network size: 15 residual blocks, 192 filters
- Value focus params applied at the beginning of the run
- 760003: KLD set to 170 (down from 340)
- 760005: KLD set to 80 (down from 170)
- 760010: KLD set to 60 (down from 80)
- 760052: KLD set to 40 (down from 60)
- 760232: Learning rate drop to 0.04, reg term weight set to 0.5
- 760434: Reg term weight set to 1.0
- 760444: Reg term weight reverted back to 0.5
- 760454: Reverted training net back to 760433
- 760489: Learning rate drop to 0.004, reg term weight to 0.15
- 760897: Reg term weight to 0.1
- 760944: Learning rate drop to 0.0004, reg term weight to 0.05
- 761257: Learning rate drop to 0.00004, reg term weight to 0.02
- End date: 2021-11-21
T75
- Start date:
- End date: 2021-10-16
T74
- Start date:
T73
- Start date:
T72
- Start date:
T71
- Start date:
T70
- Start date: 2020-02-17
- Network size: 10 residual blocks, 128 filters
- Purpose:
- 700002: KLD set to 30 micronats (up from 20)
- 700061: swa_max_n set to 10
- 700105: KLD set to 20 micronats (down from 30)
- 700140: Learning rate drop to 0.04
- 700271: Initial temp set to 1.0
- 700324: Initial temp for match games set to 1.0
- 700377: Initial temp for match games set to 1.2
- 700378: Learning rate drop to 0.004
- 700511: Initial temp set to 0.9
- 700555: Training params changed, cpuct 1.32, cpuctatroot 1.9, fpu value 0.23
- 700640: Initial temp set to 1.0, endgame temp set to 0.75, visit offset to -3
- 700699: Revert last change
- 700812: Learning rate drop to 0.0004
- 701046: Endgame temp set to 0.45, endgame-cutoff to 26
- 701124: Endgame temp set to 0.3
- 701214: Endgame temp cutoff set to 40
- 701290: Sticky-endgames enabled
- 701398: KLD set to 15 micronats (down from 20)
- 701400: KLD set to 12 micronats (down from 15)
- 701458: Training params changed, cpuctatroot 2.1
- 701463: Learning rate drop to 0.00004
- 701473: Match params synced to training params
- 701492: Learning rate raised to 0.004, Training and match params changed, cpuctatroot 1.9, KLD set to 20 micronats (up from 12)
- 701522: Endgame temp cutoff set to 32
- 701556: Temp decay set to 72
- 701603: Temp cutoff set to 60 with no decay
- 701752: Endgame temp set to 0
- 701809: Enabled gaviota moves left rescoring
- 701884: Endgame temp set to 0.45
- 701955: Endgame temp set to 0.3
- 701955: MLH attached
- 702218: Temp set to 0.9, endgame temp to 0.3, tempdecay-delay to 40, tempdecay to 30, temp cutoff to 60
- 702403: Tempdecay-delay set to 20, tempdecay to 60
- 702516: Endgame temp set to 0.4, tempdecay to 72
- 702567: Match params changed, sticky endgames enabled
- 703080: Endgame temp to 0.5, tempdecay to 90,
- 703314: Endgame temp set to 0.45
- 703460: Learning rate drop to 0.00008
- End date: 2020-7-11
T60
- Start date: 2019-07-26
- Network size: 320 filters, 24 residual blocks until 66511; 384 filters, 30 blocks from 66512
- Uses an absolute fpu of 1 at root.
- Important changes during the run (for minor changes consult the Discord log):
- 60584: Training start temperature reduced to 1.15 (was 1.2)
- 60647: Temperature further dropped to 1.1.
- 60691: Temp visit offset changed to -0.9
- 60781: Learning rate drop to 0.015
- 60951-60955: Briefly activated multinet. Deactivated due to worse game generation speed.
- 61306: Policy softmax temperature set to 1.2 (up from 1.0)
- 61433: Initial temperature to 1.3, temp decay aiming at 0 by move 23, but instead truncating at 0.4 at move 16.
- 61486: Temperature set to 1.2 decaying to 0.35
- 61538: Temperature decaying to 0.45
- 61606: Temperature set to 1.1 decaying to 0.45
- 61657: Endgame cutoff for the temperature at 22 instead of 16 (tempdecay moves to 37 instead of 26 to achieve this)
- 61708: Endgame cutoff of 26
- 61771: Learning rate drop to 0.0015
- 62479: Temperature set to 0.9 transitioning to 0.65 without decay
- 62622: Endgame temperature set to 0.75
- 62670: Lookahead optimizer introduced; LR doubled to 0.003
- 62721: Learning rate drop to 0.001
- 63022: Learning rate back up to 0.003
- 63062: CPuct set to 1.9, CPuctAtRoot remaining at 2.5
- 63158: Endgame temperature back to 0.65
- 63486: Moves left head (MLH) attached, no MLH settings active for now
- 63531: MLH parameters enabled in training (quadratic Q scaling with 0.004 slope and 0.1 max effect)
- 63828: Policy softmax temperature set to 1.4 (up from 1.2) in conjunction with noise epsilon of 0.1 and alpha of 0.12
- 63965: CPuct in tree of 1.3, CPuctAtRoot remaining at 2.5
- 64026: FpuValue set to 0.3
- 64195: Temperature set to 0.9 decaying to 0.45 (delay-moves=20, moves=80, cutoff-move=60)
- 65105: CPuct in tree of 1.6, FpuValue in tree of 0.4
- 65240: CPuct in tree of 1.3, FpuValue in tree of 0.3
- 65479: Learning rate drop to 0.0002
- 66512: Network size increased to 384x30b
- 66664: Learning rate drop to 0.00008
- 66868: Experimenting with learning rate 0.0002, endgame temp 0.5, cutoff-move 55
- 66998: Further raising endgame temp to 0.55
- 67366: Endgame temp set to 0.6
- 67673: Reduced endgame temp to 0.55
- 67739: Introduced value focus with min 0.7, slope 1.0
- 67834: Further reduced endgame temp to 0.45
- 67992: Training migrated to noob’s machine; batch splits reduced by 4x
- 68110: Value focus min set to 0.5
- 68160: Value loss weight raised to 0.8
- 68200: Deblunder started with threshold 0.1 (not active until aprox. 68380)
- 68256: Value loss weight raised to 1.6 to match T74
- 68623: Temp set to 0.9 decaying to 0.6
- 69426: Introduce 960 book, set at 2%
- 609947: Value focus min set to 0.05, slope 2.0
- 610077: Training and match params changed, cpuct 1.32, cpuctatroot 1.9, fpu value 0.23
- 610161: Introduced ‘diff focus’ with q_weight 6.0, pol_scale 3.5, focus slope 3.0, focus min 0.025
- 610269: Dirichlet noise 0.25, alpha noise, 0.30
- 610323: Tuned values applied, cpuct 0.96, fpu value 0.28
- 610885: Learning Rate drop to 0.0001, # of steps to 1000, switched to 2 gpu’s with batch size of 1024 and no splits
- 611226: Batch normalization momentum set to 0.999
- End date: 2022-01-08
T59
- Start date: 2019-12-12
- End date: 2020-02-17
- Same as T58 on termination, but no multinet
T58
- Start date: 2019-09-28
- End date: 2019-12-12
- Same as T57, plus:
- Multinet
- Temperature of 1.1
- Important changes during the run:
- 58188: Policy softmax temperature set to 1.2 (up from 1.0)
T57
- Start date: 2019-08-16
- Same as T60, except for 128 filters and 10 residual blocks.
T56
- Start date: 2019-07-25
- Same as T55, but the learning rate search will only trigger (for 1k steps) if the regularization term has gone up by more than 0.01% in the last 50 steps.
T55
- Start date: 2019-07-19
- Same training parameters as T52 to act as a comparison point (0.45 endgame temperature and 12 micronats kld)
- Focus is on whether an experimental learning rate search can reduce the time to train without reducing strength.
- Test was declared a failure on completion.
T54
- Same as T53, plus:
- Aggressive lowering of kldgain thresholds.
- Seed data (100k games) was produced by a 8x1 network with zero weights.
T53
- Same as T52, plus:
- Endgame temperature 0
T52
- Same as T51, plus:
- mask_legal_moves: Don’t require the NN to output zeros for illegal moves.
- DTZ policy boost off from the start.
- Q_ratio where the training target becomes q_ratio • q + (1-q_ratio) • z
T51
- Same as T50, plus:
- Improved settings for self-Elo matches
- Batch renorm from the start (and practice tuning hyperparams)
- FPU Reduction 0.5, 0 at root instead of -1 absolute
- DTZ policy boost (try to reduce endgame trolling)
- Disabled later in the run due to complications interacting with KLD.
T50
- 10x128 SE net
- Policy head: two 3x3 80 channel CNN (same as AZ)
- Value head: WDL (Win-Draw-Loss outputs instead of a single Q output)
- KLD (spend less time on obvious moves, more on surprising ones).
- Batch renorm added (after ?)
- Did not use: Improved settings for self-Elo matches
T40
- End date: 2019-07-26
- 20x256 SE net
- Policy head: one 1x1 80 channel CNN + FC layer
- Value head: Expected value (aka V)
- Batch renorm added (after 41546)
- Improved settings for self-Elo matches (after 41772)
T37
- 10x128 SE net
- Policy head: one 1x1 80 channel CNN + FC layer (more channels to be closer to AZ)
- Value head: Expected value (aka V)
T35
- 10x128 SE net
- Policy head: one 1x1 32 channel CNN + FC layer
- Value head: Expected value (aka V)
T30
- 20x256 net
- Policy head: one 1x1 32 channel CNN + FC layer
- Value head: Expected value (aka V)
- FPU -1 absolute (from net ?)
Older history
Summary of major changes and milestones.
-
2018-06-10, ID 396: Switch main training pipeline to use scs-ben’s bootstrapped net to try to shortcut fixing rule50 issues. Elo dropped for awhile because of this transition, but tests show the rule50 issues are mostly gone.
Run Leela Chess Zero client on a Tesla K80 GPU for free (Google Colaboratory)
Google Colaboratory (Colab) is a free tool for machine learning research. It is a Python notebook running in a Virtual Machine using an NVIDIA Tesla K80, T4, V100 and A100 GPU (a graphics processors developed by the NVIDIA Corporation).
Run Leela Chess Zero client on a Tesla T4 GPU for free (Google Colaboratory)
!!!!!!!!!! WARNING !!!!!!!!!
After abusing colab by some Lc0 clone projects, running a chess training on free tier of Colab is a disallowed activity and is throttled/banned.
Do not run the Lc0 training on Colab (at least in the free runtime).
Running a benchmark
How to run a benchmark on Windows:
-
Open the directory where Lc0 is located.
-
Hold Shift key on your keyboard and right-click on the empty space of the window, so that directory popup menu appears.
Running lc0 on Android with a Chess App
Follow these simple steps and you’ll be running lc0 on your Android device. No root needed. Just the right engine, a weights file and a supported Chess App.
Running lc0 on Android with a chess GUI
Official support
Since version 0.24, Leela Chess Zero has official support for Android. Get the APK from here:
Installable package for the latest release
https://github.com/LeelaChessZero/lc0/releases/latest
After installing the APK you will need a chess app that supports the Open Exchange protocol, like the following:
Running lczero with cuda and cudnn under nvidia docker2
If you have nvidia-docker2 installed, it’s possible to run lczero under a docker container while still leveraging all the speed advantages of CUDA and cuDNN. See https://github.com/NVIDIA/nvidia-docker for instructions on setting up nvidia-docker2
Running Leela Chess Zero as a Lichess Bot
Introduction
Lichess has developed a BOT API that allows anybody to hook up a chess engine to Lichess. Leela Chess Zero will make use of this API via the official bridge lichess-bot.
Running Leela Chess Zero on Intel CPUs (Haswell or later)
Update: While the MKL version may be useful for analysis, it will be quite slow when generating training games.
If you have an newer intel CPU and no dedicated GPU, you can boost your nps by using Intel’s Math Kernel Library. Please note that you should keep track of your CPU temperature to avoid overheating, especially if you have an older Haswell CPU. Windows Task Manager and HWInfo64 are great tools for tracking your resource usage. This guide takes into account that you have already downloaded the most recent version (http://lczero.org/play/download/) and extracted it.
Script for testing new nets versus old nets on Google Colab
Use this script to run tournaments between different versions of Leela.
https://cdn.discordapp.com/attachments/430695662108278784/436501331046563861/TestLeelaNets_v7.ipynb
TCEC S13 Issues
For TCEC Season 13, division 3, LC0 performed much worse than expected. This page summarizes the issues:
- TCEC server performance
- TCEC server is getting less NPS than expected. We expect ~26K from startpos, but only get 22K (source: jjosh in Discord).
- In div4, TCEC GPUs were overheating. For div3 fans were set to 100%, but GPUs still overheat, and we still observe lower than expected NPS.
- Some time around div3, Game 80, scs-ben used afterburner to limit the power to GPUs to 65% on one and 85% on the other. The idea is to prevent overheating which would cause performance to get even worse. Also running at a slower but constant speed may be better due do the way Time management works (needs a steady NPS). Results were much better after this workaround.
- Time management settings seem to have lc0 play too quickly in the opening.
- While investigating differences between TCEC build and v0.16 build, crem found a bug. It doesn’t seem likely this bug can explain what is going on though.
Quote from mps19 2018-08-16 at 5:17 PM. lc0_tcec shows 6 elo regression from lc0 v0.16 against AB engines instead of improvement found in self play.
Technical Explanation of Leela Chess Zero
Lc0 methods and input/output terms
A nice pictorial overview
Basics
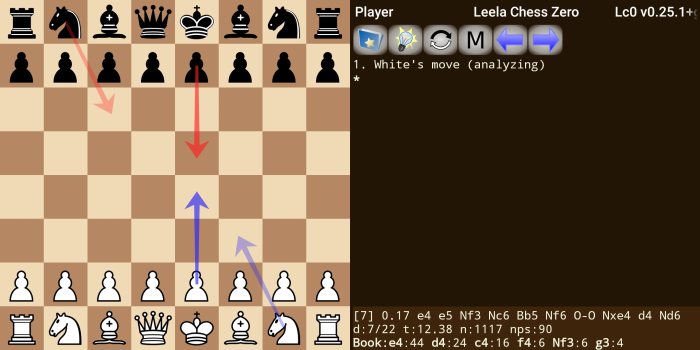
Leela searches a tree of moves and game states. Each game state is a node in the tree, with an estimated value for that position, and a prioritized list of moves to consider (called the policy for that position). Traditional chess engines have a very-finely-crafted-by-humans value and policy generation system; unlike traditional engines, Leela uses its neural network trained without human knowledge for both value and policy generation. Then, Leela expands the tree to get a better understanding of the root node, the current position.
Testing guide
So you’d like to do some engine testing with Lc0 (testing different nets, checking if your improvement increases elo, etc.). Here’s how:
Setup
- Install
cutechess-cli. Repository here.cutechess-cliis a tool that allows you to play games and tournaments between multiple engines. It is highly recommended to build from source in order to enable some openings-specific flags that are not present in the prebuilt binary releases (namely,policy=round, which allows multiple engines to play the same openings in one round). For Windows users, it is possible to grab the compiled binaries (both GUI and command line executables) posted at Leela Discord (do not download from the Releases section on github). The GUI binary is compiled with the book openings optionpolicy=roundby default. For Linux users, it is possible to compile with:
cd cutechess/projects
qmake -after "SUBDIRS = lib cli"
make
-
Install
ordo. Repository here.ordois a tool for computing elo ratings.
Third Party Nets
Outside the official training nets on https://training.lczero.org/networks/, some people are downloading the game data and training their own nets. See also: http://data.lczero.org/files/networks-contrib/
- Wiki page for all of jhorthos’s experimental nets: https://github.com/jhorthos/lczero-training/wiki/Leela-Training
- jhorthos’s T40 experiment nets: https://docs.google.com/spreadsheets/d/1-KAIfcaq5gwT90AlFNlqAWsmOehrCks86A88V47LDO0/edit#gid=1342481515
- jhorthos’s T40 experiment net T40.T8.610: https://www.dropbox.com/s/rmcf0lf1hes10gi/256x20.T8-swa-610000?dl=0
- jjosh’s Leelenstein: https://www.patreon.com/jjosh
- sergiovieri’s nets: https://github.com/sergiovieri/lc0-training/tree/master/networks
- scs-ben’s nets: http://webphactory.net/lczero
- logosgg’s 20x256 net (AKA kb3 since the filename is kb3-256x20-748000.txt.bz2):
- dkappe’s Ender nets —- specialist endgame networks: https://github.com/dkappe/leela-chess-weights/wiki/Endgame-Net
- 40x256 nets bootstrapped on T40 data: http://157.230.189.191:8080/networks/
Training data format versions
The training data generated by lc0 started with version 3 and were progressively updated to the current version 6. Earlier formats were generated by lczero.
Version 3 training data format:
Training runs
Overview
| Run # | Reference | Summary | Currently Active | Net Numbers | Best nets |
|---|---|---|---|---|---|
| NA | Old Main | Original 192x15 “main” run | No | 1 to 601 | ID595 |
| test10 | [[Lc0 Transition]] | Original 256x20 test run | No | 10'000 to 11'262 | 11250 11248 |
| test20 | Training run reset | Many changes, see blog. | No | 20'001 to 22'201 | 22018 |
| test30 | TB rescoring | Experiment with network initialization strategy, trying to solve spike issues. Experiment with Tablebase rescoring | No | 30'001 to 33'005 | 32930 |
LR Drop
| Training Run | 1st LR drop | Elo | 2nd LR drop | Elo | 3rd LR drop | Elo | Best Net | Elo | Current best |
|---|---|---|---|---|---|---|---|---|---|
| Old Main | ID 595 | 3148 | |||||||
| Test 10 | ID 10077 | ID 10320 | ID 11013 | ID 11248 | 3282 | * | |||
| Test 20 | ID 20247 | 2318 | ID 20493 | ID 21281 | ID 22018 | 3118 | |||
| Test 30 | ID 30854 |
ID for test 20 to be checked
Transposition tests
Data sets:
- FEN dataset: All positions from http://data.lczero.org/files/training_pgns/pgns-run1-20190419-1854.tar.bz2 (12'582'379 positions).
- Tree nodes after
go nodes 1000000from startpos with networkid42482. - Tree nodes after
go nodes 1000000from (middlegame) r2br3/ppq2pkp/2b2np1/4p3/6N1/2PB1Q1P/PP1B1PP1/R3R1K1 w - - 1 2 with networkid42482. - Tree nodes after
go nodes 1000000from (late middlegame) br5r/2bpkp2/B6p/2p4q/1PN1np2/P3P3/1BQ3PP/R4RK1 w - - 0 26 with networkid42482. - Tree nodes after
go nodes 1000000from (endgame) 8/8/1p1n2k1/3P2p1/3P1b2/1P1K1B2/8/4B3 w - - 2 55 with networkid42482. - Same as dataset 2 (startpos), but with 10'000'000 nodes (10 times more).
- Perpetual check position r6k/pp4pp/2p5/5Q2/1q5P/8/2P2PP1/1K1R3R w - - 1 25 from Leko vs Kramnik game.
go nodes 1000000with networkid42482. - KRN vs KR draw enggame, 6r1/6k1/8/8/8/8/3N4/2KR4 w - - 0 1.
go nodes 1000000with networkid42482.
Stats
Note: Ignore MaterialKey for now, that was crem’s idea for Lc2
Ubuntu 16
Building instructions for using CUDA backend
For Ubuntu 17.10 and 18.04 see Troubleshooting section
Should now work on 16.04 and 17.10, tested on fresh 16.04 docker and 17.10 docker
In docker image remove sudo from start of all commands that have it.
Ubuntu 16
Note: These instructions apply to the lczero.exe client, not lc0.exe. See [[lc0-transition]]
Option 1 (Sanity): Use Docker
sudo apt install docker.iosudo docker pull rcostheta/leelachesszero-mklsudo sudo docker exec -it $(sudo docker run -it -d -p 52062:22 rcostheta/leelachesszero-mkl) /file.sh <username> <password> <number of processes>
Note that the docker image is fairly large (911 MB)
What is Lc0?
Lc0 (Leela Chess Zero) is a chess engine that uses a trained neural network to play chess. It was inspired by Google’s Alpha Zero project and Lc0’s current networks have since surpassed Alpha Zero’s strength.
What is Lc0? (for non programmers)
Lc0 is often referred to as a chess engine, however, Lc0 is more like a chess engine shell than an actual chess engine. This is often called “the binary”. Lc0 needs a neural network (also called a “weights file”) in order to play, just as a car requires a driver, or a mech requires a pilot.
Why Zero
“Zero” means that no human knowledge have been added, with the exception of the rules of the game (piece movement and victory condition). Even very simple strategic concepts (e.g. it’s good to have more pieces instead of less) were not taught to Leela Chess Zero.
XLA backend
Lc0 XLA backend uses OpenXLA compiler to produce code that executes a neural network. The backend takes ONNX as an input, and converts it to the HLO format that XLA understands.