GUIDE: Setting up Leela on a Chess GUI.

Leela Chess Zero is a project started before some months inspired by Deepmind’s papers about AlphaGO Zero and AlphaZero, which is based on a new paradigm of Chess engines by not using traditional AlphaBeta search with handcrafted evaluation function but uses a variant of MCTS search called puct and for evaluation function it uses a self-taught neural network that learns by deep learning methods by playing against itself million times.
Now after 6.5 months of training it seems that it has reached a place among the top 5 strongest engines available.
Its use is not that straightforward like traditional engines since it requires some extra things one that has to make in order to run it. It’s easy thought. This guide will be about running it on **Microsoft Windows **on various GUIs.
Leela Chess Zero works with the help of 2 things:
_ •Its binary_ , that takes as inputs some weights(the evaluation
function) and produces the search.
_ •A neural net weight file_ , that is the brain of Leela and it consists
of a file(about 45 MB these times for current nets) that contains information,
that Leela generates by selfplaying, about every single aspect of Chess
strategies. This information of course is a huge pile of numbers that can’t be
understood by humans.
►Its binary initially was called lczero and was compared to the one now
was around 10 time slower or more.
Now its binary is called Lc0. It uses 3 backends, CUDA, BLAS and opencl.
CUDA is the fastest of all with a big difference and it’s for Nvidia GPUs that
support CUDA and cuDNN libraries.
OpenCL is for GPUs that do not support CUDA, for example AMD ones.
And BLAS is for running Lc0 not with a GPU, but with a CPU. That is MUCH
slower.
This means that in order to run Leela in full strength you will need a GPU
preferably one that supports CUDA.
Running it on GPU with non CUDA Lc0 binaries means you will get many times
worse performance.
Even worse running it on a CPU like normal traditional engines run, means you
will get many many times worse performance.
Neural net weights in order to run fast enough they need a GPU. On CPUs they
are slow as turtles.
Old networs were 6x64(blocks x filters) and were running very fast, main old
net in its latest stages was 15x192 so it was much slower. Now test10 and
test20 nets are 20x256 and are even more slower. Stronger of course since they
contain more information inside.
On a GTX 1070 Ti for example the nodes per second for the 10x128 nets was like
26000 N/s, while for 15x192 nets 11500 N/s and for the 20x256 nets around
5500 N/s.
Comparing different GPUs we have for fp32 precision teraflops(more is better):
GPU FP32-TFLOPS
Titan V 14.9
Titan XP 12.1
GTX 1080 Ti 11.3
GTX 1080 8.2
GTX 1070 Ti 7.8
GTX 1070 5.8
GTX 1060 6GB 3.9
GTX 1060 3GB 3.5
GTX 1050 Ti 2.1
GTX 1050 2GB 1.9
Newest RTX 2080 Ti, 2080 and 2070 cards will support fp16 precision(which is
less than fp32 one) which has been shown to boost Leela very much without
losing any strength.
Some benchmarks for the new GPUs show that Leela 20x256 gets the following
nodes per second:
fp32 fp16
GTX 1080Ti: 8996 -
Titan V: 13295 29379
RTX 2080: 9708 26678
RTX 2080Ti: 12208 32472
A Titan V costs 3000$ while the new RTX 2080 Ti will probably be around 1000$ to 1200$ so it will be a huge deal for Leela.
Lc0 binary changes from time to time, improving its search methods, adding new parameters etc. These changes, improve(normally) the search of Leela.
_ Leela’s binaries can be found here:_ https://github.com/LeelaChessZero/lc0
►Leela’s neural network weights are countless. They are generated when
contributors(that run a client that plays sefplay games of Leela) reach a
certain amount of self played by Leela games. Depending on number of
contributors one new net is produced every some 40 minutes in good times or
4-5 hours in times with less contributors. More contributors, mean more games
and more games means Leela learns even more things, so it means it gets
stronger. So the need for more and more contributors is always a necessity.
Also you can always contribute if you have a Google account without running
anything on your computer. For more on this: Google-Cloud-
guide.
Contributing is easy.
Downloading the client here: https://github.com/LeelaChessZero/lczero-
client/releases
Downloading the aforementioned binaries of Lc0 above(one of them for the
appropriate hardware, either CUDA, BLAS or Opencl).
Putting everything in one folder and then running client.exe
Leela has many series of networks. It has nets from its old main network, it
has nets for every one of 11 tests that have been made, test1, test2 etc, up
to current test20 and test 30 nets.
The strongest nets were the ones of test 10 and after that they follow the
ones of old main net.
_ These nets can be found here_ (first 3 links contain all the test10
nets as also other nets):
http://testserver.lczero.org/networks/ or http://lczero.org/networks/
http://data.lczero.org/files/networks/
http://testserver.lczero.org/old_networks/lczero.html
In order to run Leela the easiest way is to put the Lc0 binary in the same
folder with its net(weights) file and if we talk about CUDA Lc0, put all the
provided dll files in the same folder too!
Then running Lc0 is easy by specifying some parameters and then running it
like a normal UCI Chess engine.
The most basic parameter one has to specify is the weights.
Let’s say we placed Lc0.exe in a folder and many of its weight files in the
SAME folder.
Let’s now say that we want to use net 11075 that its file is called 11075(
with no extension).
►Creating the engine(more on this later), to force it use some specific
weights we should put in the parameters the:
--weights=11075
Or -w 11075
If 11075 net is in a file with an extension like 11075.txt we would obviously
put --weights=11075.txt
If 11075 net is in a file called 11075.gz and is in a different folder than
what Lc0.exe is, e.g in c:\program\weights we would put:
--weights=c:\program\weights\11075.gz
Other important parameters are:
►Cpuct value. This is a very critical parameter for search! Setting it higher
you get more exploration on the selection of which moves to think.
Yet, setting it too high you increase the chance that you search inferior
moves and lose time by searching garbage. Small values on the other hand may
mean too little exploration and so search can miss some good moves. There is
not an optimal value and it depends on the net and on other parameters like
fpu-reduction. Not setting this means it will use default 3.4 value.
--cpuct= PUCT(Predictor + Upper Confidence Bound tree search) (default:
3.4 min: 0 max: 100)
►Another critical for search parameters is fpu reduction. It makes the
evaluation of nodes that have not been visited yet, worse by a flat reduction.
This results in less exploration of unvisited and often bad nodes, while
significantly increasing the exploitation of visited nodes, and in
consequence, the search depth. Again too high or too low hurts/helps and the
“best” value is dependent on the net and on other parameters like cpuct for
example.
--fpu-reduction= First Play Urgency Reduction (default: 0.9 min: -100
max: 100)
►How many threads of CPU to use. Leela always uses CPU also for some of its
functions so we can set how many threads we want, e.g if we want 4 we put:
-t 4 or --threads=4 (min 1, maximum 128 and default 2)
Putting this parameter is optional as if we don’t put anything it will use
default number, i.e 2 threads.
►Another important search parameter is policy softmax temperature that affects
the policy output for the moves. It flattens them by exponentiating the policy
output for moves using 1/policy softmax temp as the exponent before
normalizing them to sum to 1. Higher policies get reduced, lower polices get
increased. At the extreme, for very high values of policy softmax temp, all
policy outputs end up just being equal.
--policy-softmax-temp= Policy softmax temperature (default: 2.2 min: 0.1
max: 10)
►Cache size for Leela but this has nothing to do with the usual cache for
AlphaBeta engines. It greatly affects nodes searched per time and it stores NN
evaluations, which can be reused if the same positions is reached by
transposition..
E.g for setting 400000 we use:
--nncache=400000 (default: 200000 min: 0 max: 999999999)
Putting this parameter is also optional as if we don’t put anything it will
use default number, i.e 200000.
►Backend selection. The neural network backend we want to use, e.g if we want
CUDA we put:
--backend=cudnn (default: cudnn other values: cudnn , cudnn-fp16 , check
, random , multiplexing)
Of course if we want CUDA we can also not put anything, as it will use the
default that is CUDA.
►The next 6 parameters are to change time management. They are optional also.
--slowmover= Scale thinking time (default: 2.4 min: 0 max: 100)
--move-overhead= Move time overhead in milliseconds (default: 100 min: 0
max: 10000)
**--time-curve-peak= ** Time weight curve peak ply (default: 26.2 min: -1000
max: 1000)
--time-curve-left-width= Time weight curve width left of peak (default:
82 min: 0 max: 1000)
--time-curve-right-width= Time weight curve width right of peak
(default: 74 min: 0 max: 1000)
--futile-search-aversion= Aversion to search if change unlikely
(default: 1.33 min: 0 max: 10)
►If you have syzygy endgame tablebase and you want Leela to use them in her
search you should specify the folder they are, for example if you have the
syzygy tablebases on the folder c:\endgame\ then you should put:
-s c:\endgame or --syzygy-paths=c:\endgame
If the file path contains spaces, you have to quote it. Example: “c:\endgame
tablebases”
►Putting pondering on-off:
For ON it is - -ponder for off either --no-ponder or just don’t set
this parameter at all since default is off
►Batch size. It controls how many positions the GPU can train on
simultaneously. Set as large as your GPU can handle. It affects speed
considerably.
**--minibatch-size= ** (default: 256 min: 1 max: 1024)
►Allowed node collisions per batch.
--allowed-node-collisions= Allowed node collisions, per batch (default:
32 min: 0 max: 1024)
►Maximum prefetched nodes.
--max-prefetch= Max prefetch nodes, per NN call (default: 32 min: 0 max:
1024)
►Temperature value should not be set for match play since it severely weakens
Leela. It’s just for training games.
**--temperature= ** Initial temperature (default: 0 min: 0 max: 100)
►Temperature decay is for introducing some variety in Leela’s play, while
weakening her at the same time, since it forces her not to choose the best
move all the time, but only to choose a move proportionally to how good they
are, so sometimes it may even pick a bad move, but most of the time it chooses
between 2-3 best moves. Not recommended to be enabled for having Leela in her
strongest settings. Temp decay=5 means Leela will play the first 4 moves with
tempdecay on and then with it off. For temp-decay to work it needs temperature
to be 1.
--tempdecay-moves= Moves with temperature decay (default: 0 min: 0 max:
100)
►If you want Leela to show all statistics for her move selection after every
move put:
--verbose-move-stats (default: false)
►Cache history. Length of history to include in cache.
--cache-history-length= (default: 1 min: 0 max: 7)
►Experimental parameter to save time on search when a checkmate is found.
Default is off.
--sticky-checkmate
►Creating a log file e.g leelalog.txt for when Leela running
-l leelalog.txt or --debuglog=leelalog.txt
Source: Leela’s Github and Discord.
Now, where should we put all these? Let’s then create an new Leela engine for Arena, Fritz and Cutechess GUIs:
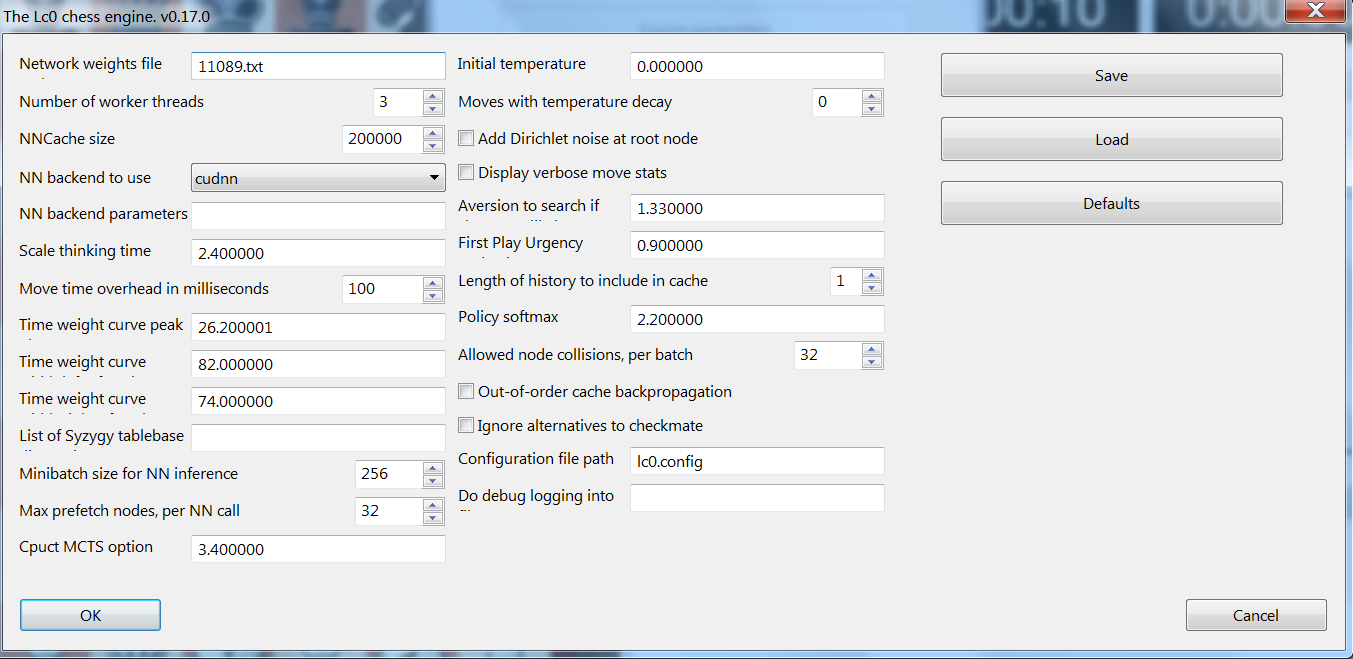
_ ►For Fritz GUI:_
•We go to ENGINE tab and then CREATE UCI ENGINE.
•Then we press the 3 dots (…) and we go to the folder the binary(+dlls +
weights) are.
•We choose the Lc0.exe and press PARAMETER.
•In there we put the parameters we want or leave it all default(we can always
change the parameters after creating the engine whenever we want) BUT we must
specify the weights file we want to use.
•So in the WEIGHTS we put for example 11089 if we have in the folder of the
Lc0 binary a file called 11089(without extension) for the net weights.
•If it’s called 11089.txt we put in the WEIGHTS 11089.txt of course.
We press OK and that’s it.
If at any moment after the creation of Leela engine, we want to change its parameters after loading it, we press its name in the analysis, press ADVANCED… and then ENGINE PARAMETERS.
(click image to zoom in)
_ ****_
_ ****_
_ ****_
_ ****_
_ ****_
_ ****_
_ **
**_ _ ****_
_ ****_
_ **
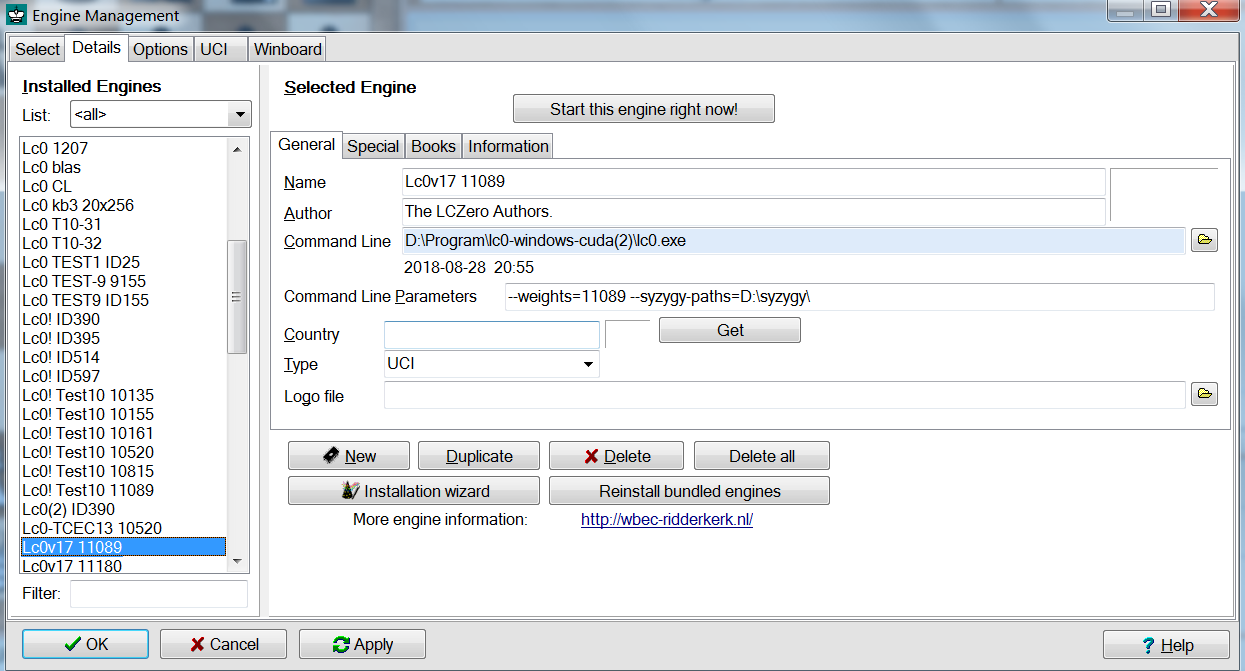
►For Arena GUI:**_
•We go to ENGINES and then to MANAGE.
•We then choose DETAILS and then NEW.
•And we then go to the folder the binary(+dlls + weights) are and we choose
the Lc0.exe.
•Then we set a name in the NAME field and then in COMMAND LINE PARAMETERS
field we put the parameters like the weights etc.
In the command line parameters, Arena has a bug and does not accept a typing
of the letter “o” so we must be careful of what we write. If we write the
letter “o”, Arena will skip it so Leela will not recognize the command, so if
we have to have a parameter or directory that contains the “o” letter we must
first to copy it from somewhere(text editor) and then press CTRL+V to paste it
in the command. That way it accepts it.
We then press OK and that’s it. (to select the engine we go ENGINES->SELECT
and then select it).
An alternative way to set parameters is to load the engine and then go to ENGINES->Engine 1->CONFIGURE.
(click image to zoom in)
_ ****_
_ **
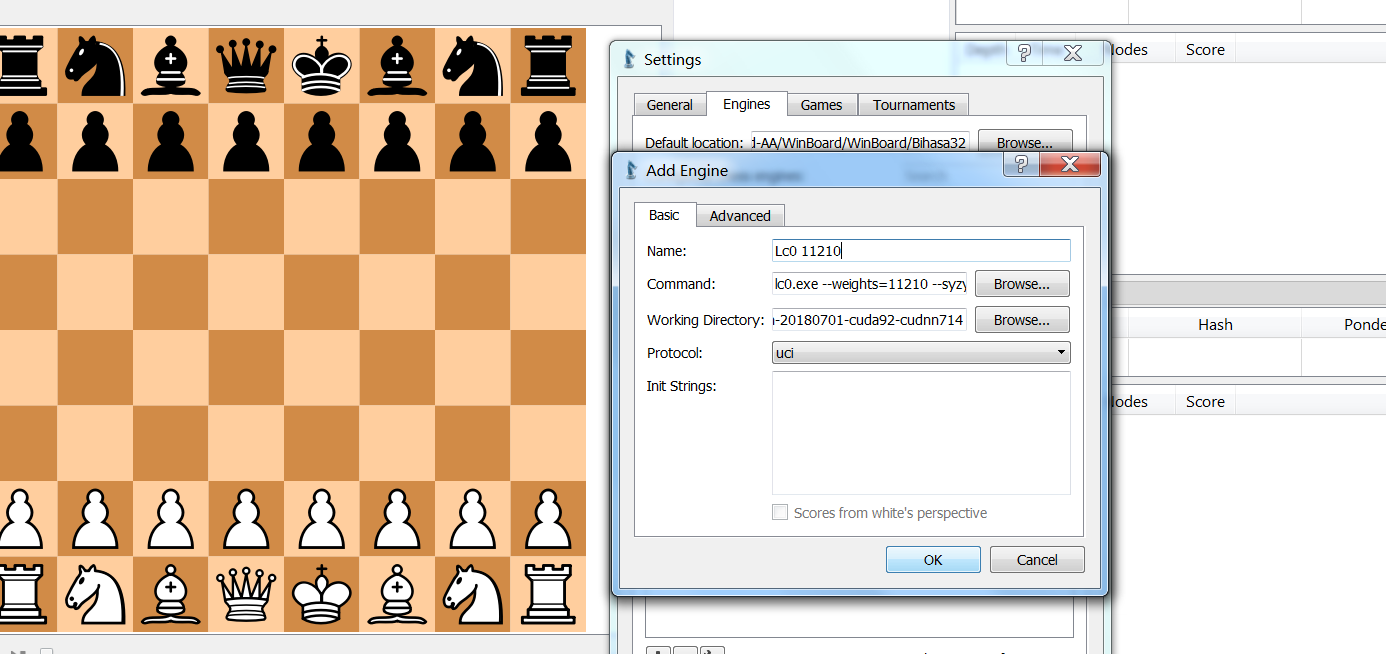
►For CuteChess GUI:**_
•We go to TOOLS->SETTINGS and then ENGINES.
•There we press the +
•And then we press the first BROWSE… of the COMMAND dialog.
•And we then go to the folder the binary(+dlls + weights) are and we choose
the Lc0.exe.
•Then in the COMMAND something like lc0.exe would be already set. After that
we put a space and we apply all the parameters we want and of course we put
the weights in there so it would say something like lc0.exe –weights=11210 if
we have a file called 11210 for the net weight in the folder of Lc0 binary we
selected.
If we want we change the name also.
(click image to zoom in)
So to sum up:
1)We grab a Lc0 binary that suits our GPU from here:
https://github.com/LeelaChessZero/lc0
2)We grab a network of our preference from here:
http://testserver.lczero.org/networks/
3)Put everything in the same folder.
4)Choose a GUI and we install Leela in the aforementioned ways.